
项目目标※
- 爬取网站上的卦象与爻辞
项目流程※
- 目标url:周易
- 分析网页元素结构
首先在初始层级,可以看到各卦象的元素命名是有规律的,用了卦象的拼音命名,用正则表达式匹配,可以轻松提取出gua_names列表,然后用循环语句进入各卦象的链接去爬取详细信息
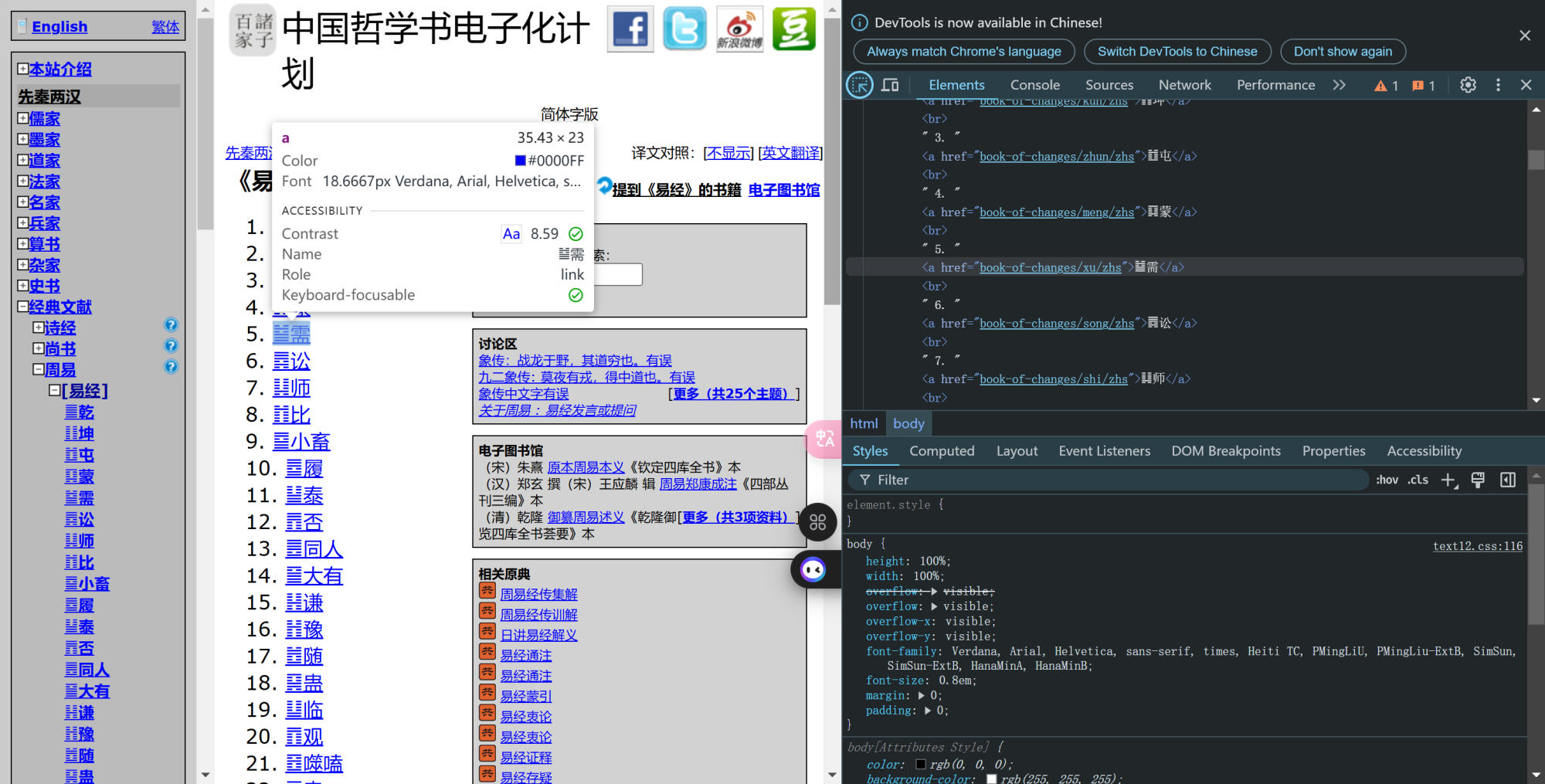
点开某一卦象的信息(以《䷃蒙》为例),查看元素,如下:
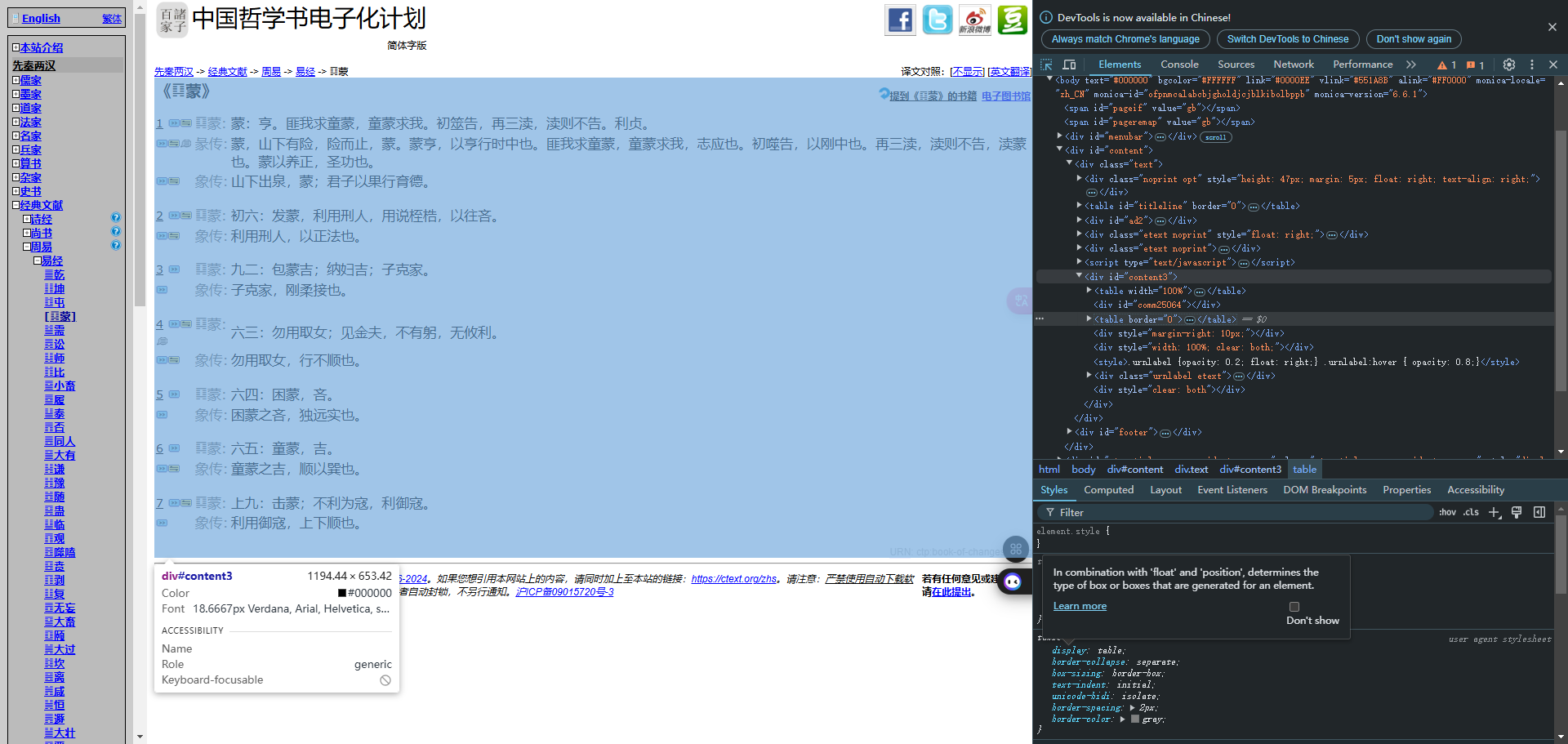
找到对应的元素位置,div:content3,从第3个td元素开始
具体程序※
温馨提示:爬虫写得好,牢饭吃到饱!大家千万不要用爬虫做不好的事情,不好的事情包括但不限于爬取公民隐私信息、爬取网站不公开信息、爬取行为对网站造成实际影响!切记!
- 提取卦象的名字,以便后续生成每一卦的url,因为网页元素比较有规律,所有这一步比较简单
import requests
from bs4 import BeautifulSoup
import re
# URL 地址
url = 'https://ctext.org/book-of-changes/yi-jing/zhs'
# 获取 HTML 内容
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
html_content = response.text
# 使用 BeautifulSoup 解析 HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 定位到特定的 div
content_div = soup.find('div', id='content3')
# 提取所有 a 标签的 href
links = [a['href'] for a in content_div.find_all('a', href=True)]
# 使用正则表达式提取相关的信息
url_pattern = re.compile(r'book-of-changes/([^/]+)')
# 提取名称
names = []
for link in links:
match = url_pattern.search(link)
if match:
names.append(match.group(1)) # 提取出匹配的部分
# 打印结果
print(names)
else:
print(f'Failed to retrieve the web page. Status code: {response.status_code}')
2. 接下来就是爬取详细内容,程序涉及异步函数,关于异步函数的具体内容,可以参考廖雪峰的官方网站的这篇:异步IO
简单来说,使用异步函数的是为了提高I/O密集操作的效率,可以同时对多个url进行请求,显著提升程序运行速度
import aiohttp # 实现异步HTTP请求
import asyncio # 用于实现异步I/O操作。
import csv
from bs4 import BeautifulSoup
from tqdm import tqdm
# 目标URL
base_url = 'https://ctext.org/book-of-changes'
# 第一步中提取的name_list
gua_names = [
'qian', 'kun', 'zhun', 'meng', 'xu', 'song', 'shi',
'bi', 'xiao-xu', 'lu', 'tai', 'pi', 'tong-ren',
'da-you', 'qian1', 'yu', 'sui', 'gu', 'lin', 'guan',
'shi-he', 'bi1', 'bo', 'fu', 'wu-wang', 'da-xu', 'yi',
'da-guo', 'kan', 'li', 'xian', 'heng', 'dun', 'da-zhuang',
'jin', 'ming-yi', 'jia-ren', 'kui', 'jian', 'jie', 'sun',
'yi1', 'guai', 'gou', 'cui', 'sheng', 'kun1', 'jing', 'ge',
'ding', 'zhen', 'gen', 'jian1', 'gui-mei', 'feng', 'lu1', 'xun',
'dui', 'huan', 'jie1', 'zhong-fu', 'xiao-guo', 'ji-ji', 'wei-ji'
]
# 生成每一卦的URL
urls = [f'{base_url}/{name}/zhs' for name in gua_names]
# 请求头部,模拟浏览器真实访问,增加访问成功率
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Referer': base_url
}
async def fetch(session, url):
"""异步获取网页内容并处理错误"""
async with session.get(url, headers=headers) as response:
response.raise_for_status() # 如果响应状态码不是200,则抛出异常
return await response.text()
async def parse_content(content):
"""解析网页内容"""
soup = BeautifulSoup(content, 'html.parser')
title_element = soup.select_one('h2')
title = title_element.get_text(strip=True) if title_element else "未知标题"
body = soup.select('table tr')
text_content = []
for row in body:
text_td = row.select_one('td:nth-child(3)')
if text_td:
text_content.append(text_td.get_text(strip=True))
return title, "\n".join(text_content)
async def main():
"""主函数,进行抓取和保存数据"""
async with aiohttp.ClientSession() as session:
with open('yi_book.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['卦象', '子网址', '内容'])
for url in tqdm(urls, desc="抓取进度"):
try:
content = await fetch(session, url)
title, text_content = await parse_content(content)
writer.writerow([title, url, text_content])
except Exception as e:
print(f"在处理 {url} 时发生错误: {e}")
# 每次请求后延时5秒,防止给目标服务器造成太大压力
await asyncio.sleep(5)
if __name__ == '__main__':
asyncio.run(main())