
汇报内容:FoodieQA 数据集与评估※
一、项目背景※
FoodieQA 是一个旨在评估和推进多模态模型(特别是视觉-语言模型(VLM)和大语言模型(LLM))对细粒度中国区域美食文化理解的多模态数据集。它通过结合图像和文本数据,考察模型在美食文化背景下的理解能力。这一数据集的构建是为了填补当前研究在文化细节、尤其是区域美食文化上的空白。
二、数据集构建过程※
数据集的目标
构建 FoodieQA 数据集的初衷是为了考察模型对中国区域美食文化的理解。中国幅员辽阔,历史悠久,不同地区的美食在食材、烹饪方法、口味偏好和呈现方式上有着显著差异。这些细微的差别不仅体现在菜品的外观,还包括文化背景与历史渊源。因此,该数据集不仅要求模型具备基础的视觉识别能力,还需要能够处理包含文化细节的复杂问题。数据收集与设计
菜系选择:
数据集包含14种中国区域菜系,扩展了经典的“八大菜系”概念,增加了西北菜、东北菜、新疆菜、内蒙古菜、黔菜和赣菜。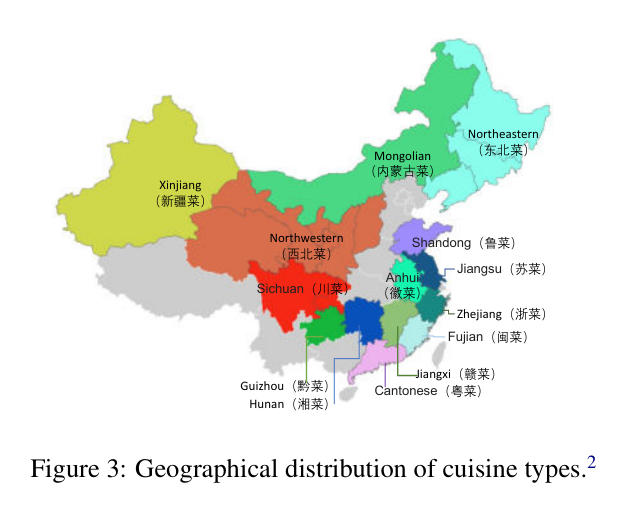
每个菜系都代表了不同的区域文化和历史背景。这种扩展使得数据集在地域覆盖上更加全面,反映了中国各地丰富的美食文化。例如:
- 四川菜(川菜):以麻辣为主,通常使用辣椒和花椒作为主要调料;
- 广东菜(粤菜):强调清淡、鲜美,常以海鲜为主;
- 山东菜(鲁菜):口味浓郁,注重使用葱姜等调料;
- 西北菜 和 新疆菜:常以面食和羊肉为主,受中亚饮食文化影响较大。
数据收集:
为了保证数据的独特性和新鲜度,研究团队没有直接使用网上现有的图片数据,而是通过微信和豆瓣等社交平台向中国本地用户发布了一份问卷。问卷邀请参与者上传他们拍摄的日常菜肴照片,要求如下:- 图片要清晰,食物为主要焦点,并且位于图片中央;
- 上传者需注明菜品所属菜系、具体菜名以及图片拍摄地点(如家中、餐馆、食堂等);
- 上传者需要确认图片未曾公开发布,确保这些图片不会出现在模型的预训练数据中。
在整个数据收集过程中,研究团队设计了详细的上传指南,最终收集到502张图片,经过筛选和质量控制后,手动筛出了103张,保留了389 张清晰、符合标准的图片。这些图片覆盖了中国主要的14种菜系,确保了区域美食的多样性。
本地特色元信息标注:
数据集不仅仅包含图片,还为每张图片配备了详细的元信息,这些信息是由来自中国不同省份的本地人根据他们的生活经验或从网络中获取的。本地标注者通过他们的知识,为每道菜提供了详尽的描述。这些描述包括17个字段,例如: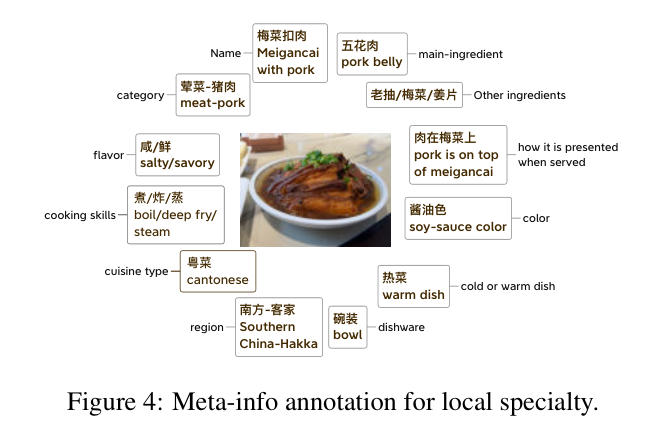
- 食品类别 (Category):肉类 - 猪肉 (Meat - Pork)
- 菜名 (Name):梅菜扣肉 (Meigancai with Pork)
- 别名 (Alternative names):无
- 主要食材 (Main ingredient):五花肉 (Pork belly)
- 主要食材的特点 (Characteristics of the main ingredient):肉在梅菜上 (Pork is on top of meigancai)
- 其他关键食材 (Other ingredients):老抽、梅菜、姜片 (Soy sauce, Meigancai, Ginger slices)
- 菜肴风味 (Flavor):咸/鲜 (Salty/Savory)
- 摆盘风格 (Presentation style):肉在梅菜上 (Pork is on top of meigancai)
- 菜肴颜色 (Dish color):酱油色 (Soy-sauce color)
- 食用温度 (Serving temperature):热菜 (Warm dish)
- 餐具 (Dishware):碗装 (Bowl)
- 产地地区 (Region):南方 - 客家 (Southern China - Hakka)
- 省份 (Province):未在图中明确指出
- 菜系类型 (Cuisine type):粤菜 (Cantonese)
- 三种主要烹饪技法 (Three primary cooking techniques):煮/炸/蒸 (Boil/Deep fry/Steam)
- 饮食习惯 (Eating habits):未在图中明确指出
- 参考链接 (Reference links):未在图中明确指出
- 通过这些标注,模型可以利用视觉特征和文本信息进行更深入的学习和推理。
问答标注设计:
多图像视觉问答(Multi-image VQA):
该任务要求模型在多个图像中进行对比,并根据问题从中选择正确的答案。这类似于人类在浏览餐馆菜单时的思考方式,问题设计要求模型不仅要识别图像中的菜品,还要结合菜品的视觉特征来进行推理。例如,问题可能会问“以下哪道菜是川菜中的凉菜?”模型必须通过对比每张图片,选择正确的答案。具体如下:问题制定:我们要求标注者撰写具有挑战性的问题,这些问题需要:(1)通过观察菜品图片来回答,(2)超越仅仅识别菜品,并涉及需要多跳推理的问题,(3)提出多样化的问题,这些问题属于多样化的提问类型,如食物类型、口味、颜色、价格、数量等,(4)每个问题只有一个图片是正确答案。多图 VQA 问题由来自中国5个不同地区的5位母语人士编写。
根据第 3.2 节所述的菜系和食品类别,将收集到的图像分为 28 组。这使得标注员可以针对从同一组中提取的相关图像依次编写问题。每位标注员针对一个包含四张图像的组别,需要编写两到三个问题。我们注意到,为了避免语言先验的偏差,图像对应的菜品名称并未展示。我们使用的标注用户界面如图 12 所示。

在收集到多图多选题的题目和答案后,我们通过让标注员(他们没有创建题目)回答这些问题来验证题目。如果一个题目不符合我们定义的标准,标注员将被指示将其标记为“不良问题”。在此过程中,共丢弃了 87 个问题。此外,在回答问题时,标注员需要提供他们得出答案的理由,并判断该问题是否需要多跳推理。我们用于验证的用户界面如图 13 所示。每个问题都由两位标注员进行验证,我们排除那些没有达成完全一致意见的问题。

- 单图像视觉问答(Single-image VQA):
在单图像任务中,模型只需对一张图片进行细粒度分析,回答与该图片相关的文化问题。这类问题通常涉及到具体菜品的主要成分、烹饪方法或口味特点。例如,“这道菜的主要成分是什么?”、“这道菜属于哪个菜系?”。具体如下:- 问题制定:基于同一元字段多次提问的问题,通过改变因素如菜肴的图片,而答案选项则从元字段中的错误候选人中精心挑选,以确保只有一个正确答案。单图 VQA 问题采用基于规则的生成方法,随后进行彻底的人工验证,与多图 VQA 验证过程类似。
- 问题验证:问题验证与多图像 VQA 问题的验证类似,标注员需要根据文本查询和相应的图像来回答问题,并对不符合标准的问题提出“问题不良”的标记以过滤掉这些问题。共有 88 个问题被判定为不良。请注意,文本问题中没有透露菜肴的名称,因此需要根据视觉信息来回答问题。如果标注员认为问题超出了他们的知识范围,他们需要在理由中写下“我不知道”,并随机猜测一个答案。
- 文本问答(Text QA):
文本问答任务不依赖图片,仅使用文本进行回答。问题多为文化知识类,要求模型具备对中国美食文化的深刻理解。例如,“白切鸡的主要口味是什么?”、“这道菜是哪个地区的特色菜?”。具体如下:- 我们通过结合人工标注和基于规则的生成来构建文本问题。与单图像 VQA 方法类似,我们根据元信息字段生成了问题和多项选择题选项。然而,我们不是使用菜品图像,而是在问题中直接包含了菜品名称。
- 问题是通过模板构建的,其中只有菜品名称和元字段会变化。还包含了与单图像问题回答相同的人为验证过程。共丢弃了 135 个不良问题。请注意,标注者被要求根据他们的知识回答问题,而不使用搜索引擎,这使得任务更具挑战性,因为如果没有其他可用信息(除了食品名称)来了解不熟悉的食品和地区,回答这些问题将非常困难。
问题验证与筛选 所有设计的问题都经过了严格的双人审核过程。审核者不是问题设计者,确保问题的客观性和合理性。在审核过程中,如果问题的难度过大或设计不合理(如无法根据图像或文本得出答案),这些问题会被标记为“无效问题”。最终,有效的问题分为三类:
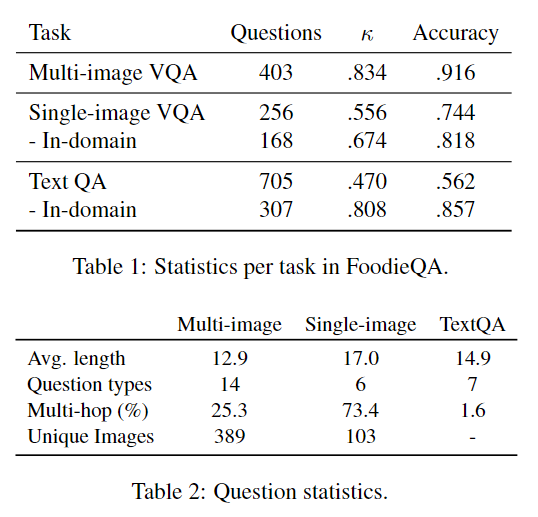
多图像VQA:403道问题;
单图像VQA:256道问题;
文本问答:705道问题。
三、数据集的评估过程※
模型评估方法 FoodieQA 的主要目标是评估当前最先进的多模态模型和大语言模型在处理中国区域美食文化上的表现。研究团队采用零样本学习(Zero-shot Learning)的方法,直接评估模型在未经训练的数据集上的表现。通过这种方式,可以更好地测试模型在没有明确预训练目标的情况下,如何处理与区域文化相关的细粒度任务。具体规则如下:
我们评估了开放权重和基于 API 的顶级模型LLMs和 VLMs,以探究它们在食品领域的文化知识。我们在中英文两种语言下对 VQA 任务进行了模型评估。问题使用 DeepL 免费 API 翻译成英文,并由两位母语为中文且精通英语的博士生进行验证。为了避免在翻译菜名时产生偏差,我们仅在中文环境下进行 TextQA 任务。
参与评估的模型包括多种开源和闭源模型:
- 开源模型:如 Phi-3-vision、Idefics2、Qwen-VL-12B、Yi-VL 系列等;
- 闭源API:如 GPT-4V 和 GPT-4o。
这些模型均支持处理多模态数据(图像和文本),能够在图像基础上进行推理或在纯文本环境下回答文化相关的问题。
多图像视觉问答(VQA)评估 在多图像VQA任务中,模型需要根据四张不同的图片回答与菜品相关的视觉问题。这类任务要求模型不仅能识别图片中的食物,还要能够根据视觉线索推断出菜品的区域来源、烹饪方式或口味特点。
我们尝试了四种不同的提示,这些提示使用了图像和文本列表或交错图像-文本输入。
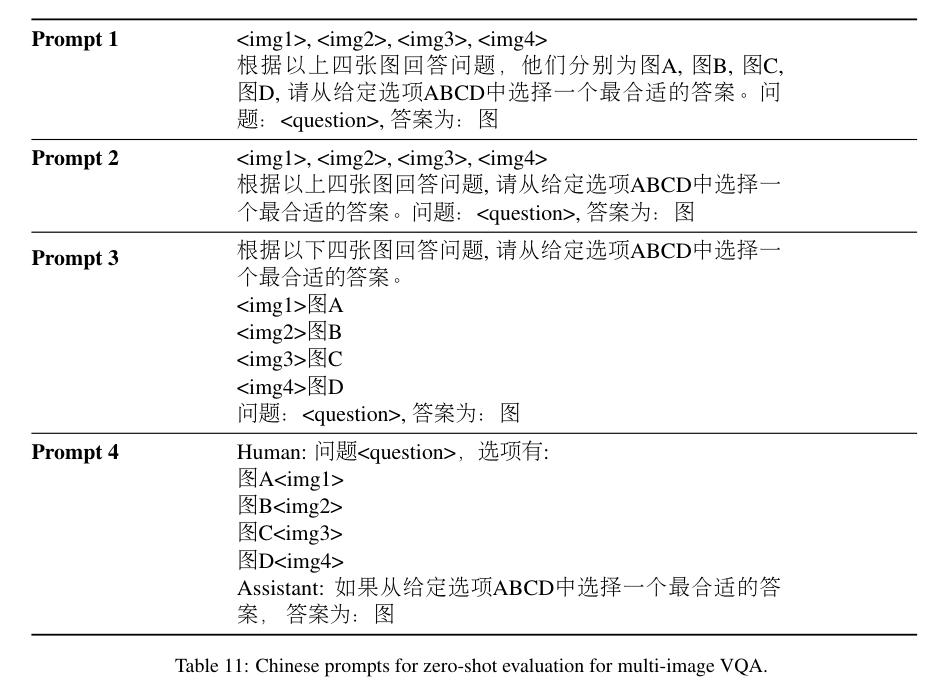
- 人类表现:人类在多图像任务中的准确率为91.69%,这是该任务的baseline;
- 模型表现:最好的开源模型 Idefics2-8B 在此任务中的表现为50.87%,远低于人类表现。这表明多图像对比、特别是涉及到文化知识的问题,仍然是当前模型的一大挑战。(Plus: 在翻译成英文问题进行评估时,除了 Phi-3-vision 之外,所有模型的性能都下降了。)
模型的表现差异显著,主要原因是它们难以结合视觉信息与文化背景进行多层次的推理。例如,当问到“哪个菜品是东北菜的代表?”时,模型需要能够识别每张图片的食物特征,并将其与区域美食文化联系起来,才能得出正确答案。
单图像视觉问答评估
单图像任务要求模型根据单张图片回答问题,尽管比多图像任务简单,但依然考察了模型对文化细节的理解。例如,模型可能需要回答菜肴的主要成分、烹饪方式、区域来源等问题。在此类任务中,模型的表现如下:
- 人类表现:人类的平均准确率为 74.41%。
- 模型表现:双语模型(如Qwen-VL, Yi-VL-34B)表现尤为突出,尤其在中文问题上。该模型在单图像任务中的准确率为 52.73%,这表明双语模型在处理与中国美食文化相关的问题时表现出色。(Plus: 对于多语言模型,即 Phi-3、Idefics2 和 Mantis-8B,它们在英文评估时的表现更佳。)
视觉信息的重要性:实验还表明,当提供完整的视觉信息时,模型的表现显著提高。相比只提供文本提示,给出菜品的图像可以让模型更好地识别出菜品的视觉特征(如颜色、质地、形状等),进而推理出更准确的答案。例如,提供菜名和图片时,模型的表现明显优于只提供菜名。
文本问答评估
在文本问答任务中,模型不依赖于任何视觉输入,而是通过对文本进行推理来回答问题。这类任务主要考察模型对中国美食文化知识的理解能力,问题的范围包括菜品的主要成分、烹饪方式、口味、区域特色等。
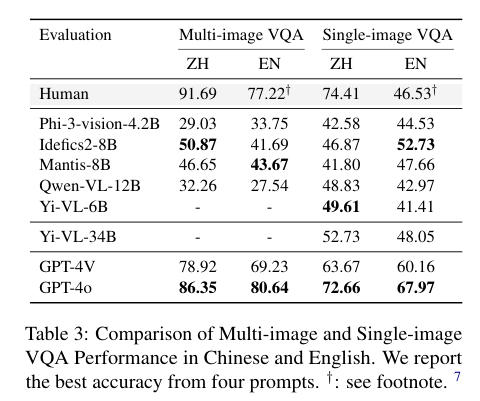
- 人类表现:在人类标注的文本问答任务中,平均准确率为 56.2%。
- 模型表现:模型在纯文本环境下表现非常出色,特别是大语言模型(LLMs)。如 Qwen2-7B 模型在此任务中的准确率超越了人类表现,表明模型在处理包含丰富知识的文化类问题时,能够充分发挥其预训练的语义理解能力。其他模型如 GPT-4 的表现同样令人印象深刻,显示出其在处理细粒度文化背景知识方面的强大能力。
文本任务的高准确率很大程度上得益于模型在预训练过程中积累的广泛知识,或由于这些局部专业标注是由当地代表收集和总结的,可能还包含了来自百度百科等公共网络资源的有关信息,因此高性能可能归因于领域特定训练数据的包含。
四、实验分析与发现※
多图像任务的挑战
FoodieQA 数据集展示了多图像任务的复杂性,即使是目前最先进的视觉-语言模型,仍在这些任务中表现较差。多图像任务需要模型不仅能识别每个菜品,还要能够从多张图像中进行对比,并推理出菜品所属的区域或菜系。这不仅是对视觉识别能力的挑战,更是对文化背景知识的考验。例如,当给定四张来自不同菜系的菜品图片,模型需要从中识别出哪一道菜属于四川凉菜。这样的任务要求模型具备识别复杂食物特征的能力,同时还要结合川菜的区域文化特征来得出正确答案。最好的开源模型 Idefics2-8B 在这种任务中的准确率仅为 50.87%,显著低于人类的表现,表明当前模型在处理此类任务时仍有很大改进空间。
单图像任务中的视觉信息优势
单图像任务提供了模型识别细节的机会,尤其是在涉及食物的视觉特征时,如颜色、质地和器皿类型等。实验表明,当模型仅依赖文本时,它们的表现相对较弱,而结合图像信息后,模型的表现显著提升。例如,实验设计了两种情况:一种是只提供菜品名称,另一种是同时提供菜品名称和图片。结果显示,结合图片的模型表现更好。例如,Idefics2-8B 模型在有图片支持的情况下,准确率比仅有文本提示的任务高出10%左右。这表明,视觉信息对于提高模型的推理能力至关重要,特别是在涉及复杂的食物文化时。

双语模型在中文环境中的优势
由于 FoodieQA 数据集主要关注中国美食文化,双语模型(如 Qwen-VL 和 Yi-VL)在处理中文问题时表现出色。相比其他主要基于英文训练的模型,双语模型能够更好地理解与中文相关的细节,尤其是在单图像和文本问答任务中。例如,Yi-VL 系列模型在中文环境下的表现普遍优于英文任务。这表明,双语模型不仅能够处理多语言任务,还能够更好地适应文化背景的变化。通过与中文训练语料库的结合,这些模型能够更准确地识别与中国美食文化相关的视觉和文本信息。
文本问答中的文化知识表现
文本问答任务中,模型在处理纯文本信息时展现出了强大的文化知识理解能力,特别是在区域美食文化上。例如,许多模型能够准确回答诸如“阳澄湖大闸蟹属于哪个菜系?”这样的问题。模型在不同食物类别与菜系类型问题上的表现
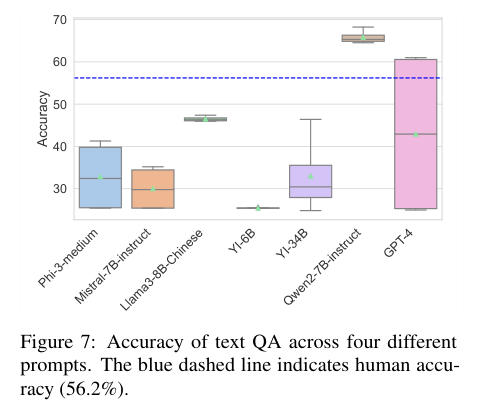
模型在某些具有明确视觉特征的类别上表现较好,但在视觉模糊或文化依赖较强的问题上,模型表现不理想。在多图像视觉问答任务中,整体表现最佳的模型在关于烧烤和新疆菜的问题上表现出色,但在关于上海菜的问题上表现较弱。另一个有趣的发现是,尽管四川菜是中国最受欢迎的菜系之一,并且可能拥有更多的在线图像和资源,但没有任何模型在回答与这种菜系相关的问题上表现出色。
VQA 任务中的细粒度问题表现
模型在处理涉及视觉特征明确(如烹饪技巧、主要食材、菜肴呈现方式等)的细粒度问题时表现较好,而对于那些依赖文化背景知识(如风味、地域、菜系类型等)的细粒度问题则表现较差。这揭示了当前视觉-语言模型在处理与美食相关的视觉和文化理解任务时的不足之处。未来的改进方向可能在于增加对文化背景的预训练数据,或是提升模型在抽象特征推理中的表现,以更好地应对细粒度的文化背景问题。
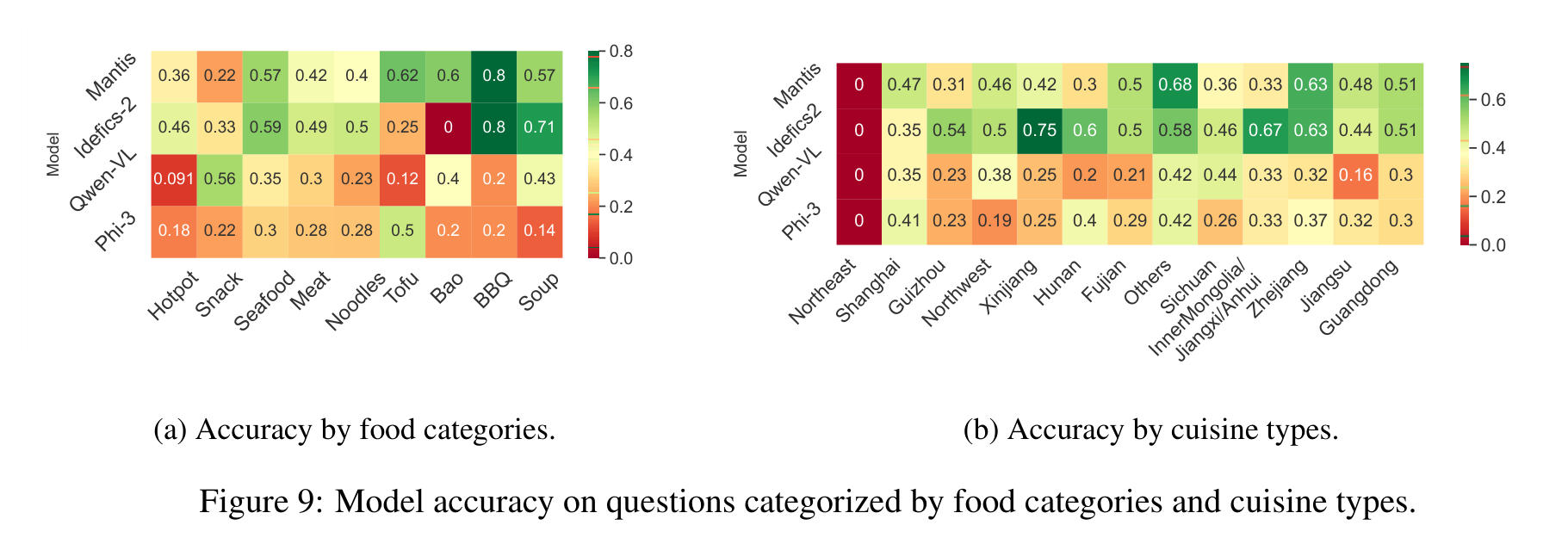
图 8a 展示了模型在单图和多图 VQA 中针对细粒度问题属性的表现。我们观察到,所有模型在回答与烹饪技巧和食材相关的问题上通常表现优秀。特别是 Yi 模型,在识别菜肴风味方面展现出更强的能力。相反,Qwen-VL 和 Phi3-vision 模型在观察食物的呈现方式时表现良好,但在与风味相关的问题上则显得有些吃力。在基于多图回答问题时,这一点同样适用,模型在关于烹饪技巧和食物数量的问题上通常表现不错(图 8b)。然而,这些模型在回答与菜肴地域和风味相关的问题上较弱。Idefics-8B 在大多数我们评估的细粒度特征上表现出色。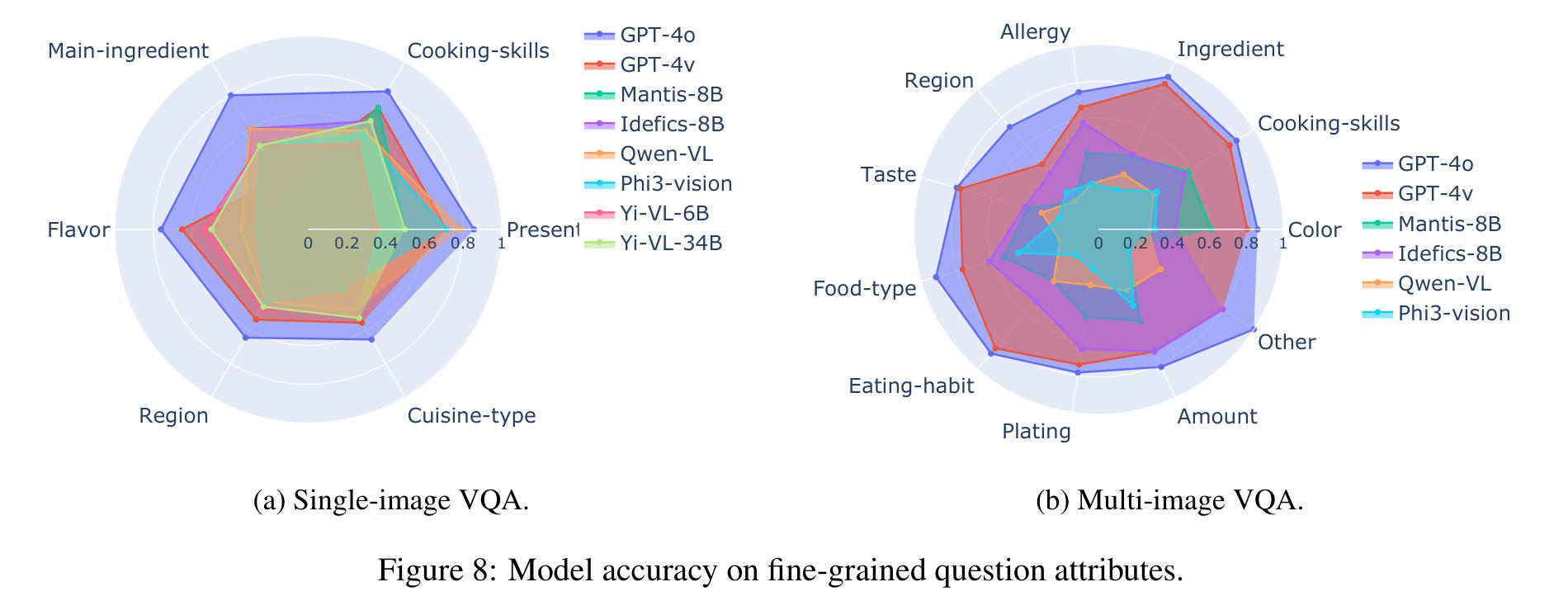
五、结论与未来展望※
FoodieQA 数据集的构建为多模态模型提供了一个全新的测试平台,尤其是在美食文化理解方面。通过数据集的多样性和复杂性,研究发现当前的视觉-语言模型在处理涉及区域文化细节的任务时仍然面临巨大挑战,尤其是在多图像任务上,模型与人类表现存在显著差距。
多模态模型的改进方向
当前的研究表明,模型在视觉任务上,特别是与文化相关的多图像推理上仍有很大提升空间。未来的改进可能需要在预训练阶段引入更多的文化背景信息,或者设计更复杂的视觉-语言对齐机制,以便更好地捕捉不同区域美食的细节差异。扩展到其他文化和领域
未来,FoodieQA 数据集的使用场景不仅限于中国美食文化,它还可以扩展到其他国家和地区的美食文化。这种扩展将有助于构建更具全球性、跨文化理解能力的模型。通过丰富不同地区的美食数据集,研究人员可以更好地评估模型在多文化环境中的表现,并推动其在美食推荐系统、智能菜单设计等实际应用中的发展。社区贡献与未来方向
FoodieQA 项目已在 Hugging Face 平台上公开,研究人员和开发者可以自由访问和使用该数据集(项目地址)。社区也可以在此基础上继续扩展数据集,针对不同文化背景进行本地化应用。未来,研究团队希望通过社区合作,进一步丰富这一数据集,并为全球范围内的美食文化理解研究做出贡献。
六、总结※
FoodieQA 数据集为视觉-语言模型的文化理解提供了全新的测试基准,尤其是针对中国区域美食文化的细粒度任务。研究表明,当前的多模态模型在面对文化背景和细节时,表现仍有不足。未来的研究应着重提升模型的视觉-文化推理能力,尤其是在多图像对比和文化背景知识方面,以便更好地理解和应对全球范围内的文化复杂性。
