
In [ ]:
# 在新python环境中进行训练,以下均为最新版本库
import re
import os, glob, datetime, time
import numpy as np
import torch
import torch.nn as nn
from torch.nn.modules.loss import _Loss
import torch.nn.init as init
from torch.utils.data import DataLoader
import torch.optim as optim
from torch.optim.lr_scheduler import MultiStepLR
import data_generator as dg
from data_generator import DenoisingDataset
import torch.cuda as cuda
nn.Module.dump_patches = True
In [19]:
# 使用默认的训练参数
batch_size = 256
train_data = './data/train/'
sigma = 25
n_epoch = 180
lr = 1e-3
# 创建保存模型的目录
save_dir = os.path.join('./models', 'DnCNN_sigma' + str(sigma))
if not os.path.exists(save_dir):
os.makedirs(save_dir)
In [20]:
# 定义DnCNN模型
class DnCNN(nn.Module):
def __init__(self, depth=21, n_channels=64, image_channels=1, use_bnorm=True, kernel_size=3):
super(DnCNN, self).__init__()
kernel_size = 3
padding = 1
layers = []
layers.append(nn.Conv2d(in_channels=image_channels, out_channels=n_channels, kernel_size=kernel_size, padding=padding, bias=True))
layers.append(nn.ReLU(inplace=True))
for _ in range(depth-2):
layers.append(nn.Conv2d(in_channels=n_channels, out_channels=n_channels, kernel_size=kernel_size, padding=padding, bias=False))
layers.append(nn.BatchNorm2d(n_channels, eps=0.0001, momentum = 0.95))
layers.append(nn.ReLU(inplace=True))
layers.append(nn.Conv2d(in_channels=n_channels, out_channels=image_channels, kernel_size=kernel_size, padding=padding, bias=False))
self.dncnn = nn.Sequential(*layers)
self._initialize_weights()
def forward(self, x):
y = x
out = self.dncnn(x)
return y-out
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.orthogonal_(m.weight)
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
# 定义损失函数
class sum_squared_error(_Loss):
"""
Definition: sum_squared_error = 1/2 * nn.MSELoss(reduction = 'sum')
The backward is defined as: input-target
"""
def __init__(self, size_average=None, reduce=None, reduction='sum'):
super(sum_squared_error, self).__init__(size_average, reduce, reduction)
def forward(self, input, target):
return torch.nn.functional.mse_loss(input, target, size_average=None, reduce=None, reduction='sum').div_(2)
# 查找最新的检查点
def findLastCheckpoint(save_dir):
file_list = glob.glob(os.path.join(save_dir, 'model_*.pth'))
if file_list:
epochs_exist = []
for file_ in file_list:
result = re.findall(".*model_(.*).pth.*", file_)
epochs_exist.append(int(result[0]))
initial_epoch = max(epochs_exist)
else:
initial_epoch = 0
return initial_epoch
# 日志函数
def log(*args, **kwargs):
print(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S:"), *args, **kwargs)
In [ ]:
# 训练过程
# 创建模型实例
model = DnCNN()
# 查找最新的检查点
initial_epoch = findLastCheckpoint(save_dir=save_dir)
if initial_epoch > 0:
print('resuming by loading epoch %03d' % initial_epoch)
# 添加weights_only=False明确声明,或考虑使用state_dict方式加载
try:
model = torch.load(os.path.join(save_dir, 'model_%03d.pth' % initial_epoch), weights_only=False)
except TypeError: # 如果您的PyTorch版本过低,不支持weights_only参数
model = torch.load(os.path.join(save_dir, 'model_%03d.pth' % initial_epoch))
model.train()
# 初始化损失函数和优化器
criterion = sum_squared_error()
if cuda:
model = model.cuda()
optimizer = optim.Adam(model.parameters(), lr=lr)
# 学习率调度策略
scheduler = MultiStepLR(optimizer, milestones=[30, 60, 90], gamma=0.2)
# 修改源代码,设置早停机制
best_loss = float('inf') # 初始最小损失为正无穷
patience = 10 # 最多允许10个epoch没有提升
epochs_without_improvement = 0 # 计数器
# 训练损失
train_loss = []
# 训练循环
for epoch in range(initial_epoch, n_epoch):
# 生成训练数据
xs = dg.datagenerator(data_dir=train_data)
xs = xs.astype('float32') / 255.0
xs = torch.from_numpy(xs.transpose((0, 3, 1, 2))).float()
DDataset = DenoisingDataset(xs, sigma)
DLoader = DataLoader(dataset=DDataset, num_workers=4, drop_last=True, batch_size=batch_size, shuffle=True)
epoch_loss = 0
start_time = time.time()
for n_count, batch_yx in enumerate(DLoader):
optimizer.zero_grad() # 梯度置零
if cuda:
batch_x, batch_y = batch_yx[1].float().cuda(), batch_yx[0].float().cuda()
else:
batch_x, batch_y = batch_yx[1].float(), batch_yx[0].float()
loss = criterion(model(batch_y), batch_x)
epoch_loss += loss.item()
loss.backward()
optimizer.step()
if n_count % 10 == 0:
print('%4d %4d / %4d loss = %2.4f' % (epoch+1, n_count, xs.size(0) // batch_size, loss.item() / batch_size))
# 在每个epoch结束后调用scheduler.step()
scheduler.step()
elapsed_time = time.time() - start_time
train_loss.append(epoch_loss / n_count)
log('epoch = %4d, loss = %4.4f, time = %4.2f s' % (epoch+1, epoch_loss / n_count, elapsed_time))
np.savetxt('train_result.txt', np.hstack((epoch+1, epoch_loss / n_count, elapsed_time)), fmt='%2.4f')
# 检查当前epoch损失是否为最佳损失
if epoch_loss / n_count < best_loss:
best_loss = epoch_loss / n_count
epochs_without_improvement = 0
# 保存当前模型为最佳模型
torch.save(model.state_dict(), os.path.join(save_dir, 'best_model.pth'))
print(f"Best model saved at epoch {epoch+1} with loss = {best_loss:.4f}")
else:
epochs_without_improvement += 1
print(f"No improvement in epoch {epoch+1}, {epochs_without_improvement} epochs without improvement.")
# 如果没有提升的epoch数超过设定的耐心值,则早停
if epochs_without_improvement >= patience:
print(f"Early stopping triggered at epoch {epoch+1}")
break
# 使用state_dict方式保存模型,避免序列化问题
torch.save(model.state_dict(), os.path.join(save_dir, 'model_state_%03d.pth' % (epoch+1)))
# 仍保留原来的保存方式,以兼容旧代码
torch.save(model, os.path.join(save_dir, 'model_%03d.pth' % (epoch+1)))
In [ ]:
# 可视化训练损失
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(train_loss)+1), train_loss, 'r-')
plt.title('DnCNN Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.grid(True)
plt.savefig('train_loss.png')
plt.show()
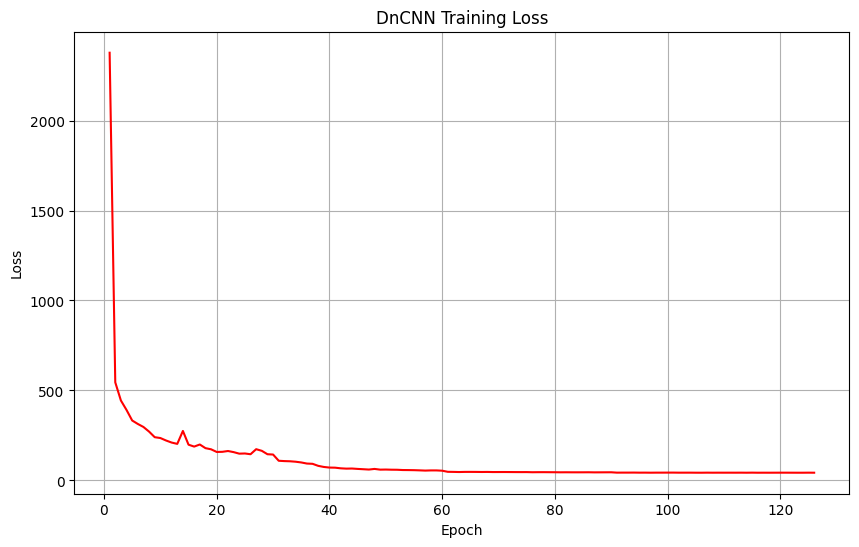
- 训练结果:可视化如图,训练在135轮停止,best model为model_125
In [1]:
import os, time, datetime
import numpy as np
import torch.nn as nn
import torch.nn.init as init
import torch
# from skimage.measure import compare_psnr, compare_ssim 改成下面这两句
from skimage.metrics import peak_signal_noise_ratio as compare_psnr
from skimage.metrics import structural_similarity as compare_ssim
from skimage.io import imread, imsave
import matplotlib.pyplot as plt
import random
import warnings
warnings.filterwarnings("ignore")
# 设置参数
set_dir = './data'
set_names = ['Set68', 'Set12']
sigma = 25
model_dir = r'D:\Download\dncnnb_pytorch\dncnnb_pytorch\models\DnCNN_sigma25'
model_name = r'model_125.pth'
result_dir = r'D:\Download\dncnnb_pytorch\dncnnb_pytorch\models'
save_result = 1
# 创建结果目录
if not os.path.exists(result_dir):
os.makedirs(result_dir)
In [2]:
def log(*args, **kwargs):
print(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S:"), *args, **kwargs)
def save_result(result, path):
result = np.clip(result, 0, 1)
result = (result * 255).astype(np.uint8)
imsave(path, result, plugin='imageio')
def show(x, title=None, cbar=False, figsize=None):
plt.figure(figsize=figsize)
plt.imshow(x, interpolation='nearest', cmap='gray')
if title:
plt.title(title)
if cbar:
plt.colorbar()
plt.show()
# 定义模型
class DnCNN(nn.Module):
def __init__(self, depth=21, n_channels=64, image_channels=1, use_bnorm=True, kernel_size=3):
super(DnCNN, self).__init__()
kernel_size = 3
padding = 1
layers = []
layers.append(nn.Conv2d(in_channels=image_channels, out_channels=n_channels, kernel_size=kernel_size, padding=padding, bias=True))
layers.append(nn.ReLU(inplace=True))
for _ in range(depth-2):
layers.append(nn.Conv2d(in_channels=n_channels, out_channels=n_channels, kernel_size=kernel_size, padding=padding, bias=False))
layers.append(nn.BatchNorm2d(n_channels, eps=0.0001, momentum=0.95))
layers.append(nn.ReLU(inplace=True))
layers.append(nn.Conv2d(in_channels=n_channels, out_channels=image_channels, kernel_size=kernel_size, padding=padding, bias=False))
self.dncnn = nn.Sequential(*layers)
self._initialize_weights()
def forward(self, x):
y = x
out = self.dncnn(x)
return y-out
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.orthogonal_(m.weight)
print('init weight')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
In [3]:
# 加载模型
model_path = os.path.join(model_dir, model_name)
model = torch.load(model_path
if os.path.exists(model_path)
else os.path.join(model_dir, 'model.pth'), map_location='cpu', weights_only=False)
In [4]:
for set_cur in set_names:
if not os.path.exists(os.path.join(result_dir, set_cur)):
os.mkdir(os.path.join(result_dir, set_cur))
psnrs = []
ssims = []
# 获取所有图像文件名
image_files = [im for im in os.listdir(os.path.join(set_dir, set_cur)) if im.endswith(".jpg") or im.endswith(".bmp") or im.endswith(".png")]
# 随机选择 3 张图像
selected_images = random.sample(image_files, 3)
for im in selected_images:
x = np.array(imread(os.path.join(set_dir, set_cur, im)), dtype=np.float32) / 255.0
np.random.seed(seed=10086)
y = x + np.random.normal(0, sigma / 255.0, x.shape) # 加噪
y = y.astype(np.float32)
y_ = torch.from_numpy(y).view(1, -1, y.shape[0], y.shape[1])
start_time = time.time()
y_ = y_ # 不需要.cuda(),因为使用cpu测试
x_ = model(y_)
x_ = x_.view(y.shape[0], y.shape[1])
x_ = x_.cpu()
x_ = x_.detach().numpy().astype(np.float32)
elapsed_time = time.time() - start_time
print('%10s : %10s : %2.4f second' % (set_cur, im, elapsed_time))
psnr_x_ = compare_psnr(x, x_)
ssim_x_ = compare_ssim(x, x_, data_range=1.0) # 增加参数
# 拼接原图、加噪图和去噪图
comparison_image = np.hstack((x, y, x_))
if save_result:
name, ext = os.path.splitext(im)
show(comparison_image, title=f'{name} | Original | Noisy | Denoised', figsize=(15, 5)) # 显示拼接图
save_result(x_, path=os.path.join(result_dir, set_cur, name + '_dncnn' + ext)) # 保存去噪图
psnrs.append(psnr_x_)
ssims.append(ssim_x_)
psnr_avg = np.mean(psnrs)
ssim_avg = np.mean(ssims)
psnrs.append(psnr_avg)
ssims.append(ssim_avg)
print(f"\nAverage PSNR: {psnr_avg:.2f} dB")
print(f"Average SSIM: {ssim_avg:.4f}")
Set68 : test039.png : 0.9930 second

Set68 : test063.png : 0.9748 second

Set68 : test037.png : 1.1789 second

Average PSNR: 28.89 dB
Average SSIM: 0.8155
Set12 : 11.png : 1.6031 second

Set12 : 12.png : 1.7630 second

Set12 : 06.png : 0.6925 second
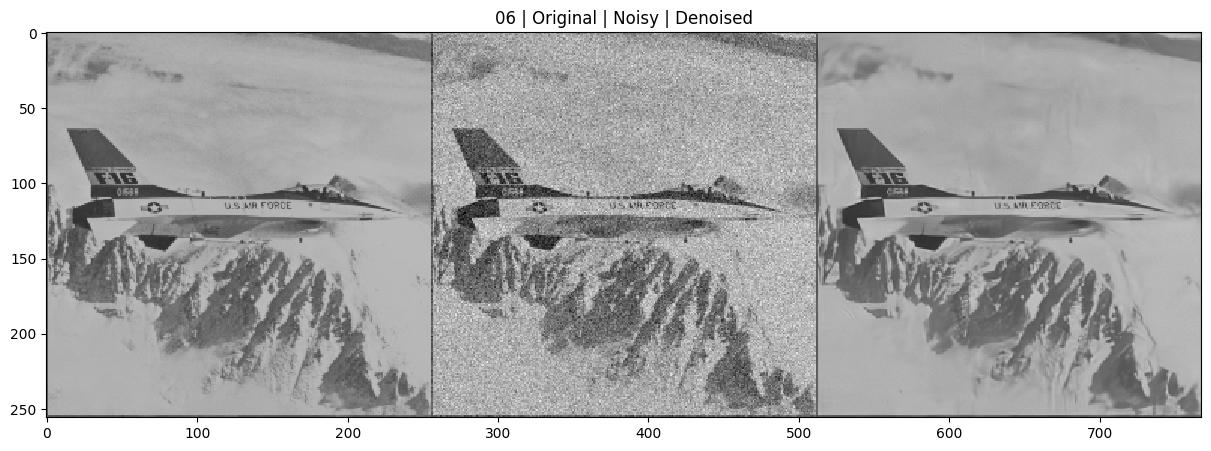
Average PSNR: 29.39 dB Average SSIM: 0.8196
